10. Semantic Segmentation and FCN's
Semantic Segmentation
In semantic segmentation, we want to input an image into a neural network and we want to output a category for every pixel in this image. For example, for the below image of a couple of cows, we want to look at every pixel and decide: is that pixel part of a cow, the grass or sky, or some other category?

Small image of cows in a field.
We’ll have a discrete set of categories, much like in a classification task. But instead of assigning a single class to an image, we want to assign a class to every pixel in that image. So, how do we approach this task?
Fully-Convolutional Network (FCN) Approach
If your goal is to preserve the spatial information in our original input image, you might think about the simplest solution: simply never discard any of that information; never downsample/maxpool and don’t add a fully-connected layer at the end of the network.
We could use a network made entirely of convolutional layers to do this, something called a fully convolutional neural network. A fully convolutional neural network preserves spatial information.
This network would take in an image that has true labels attached to each pixel, so every pixel is labeled as grass or cat or sky, and so on. Then we pass that input through a stack of convolutional layers that preserve the spatial size of the input (something like 3x3 kernels with zero padding). Then, the final convolutional layer outputs a tensor that has dimensions CxHxW, where C is the number of categories we have.
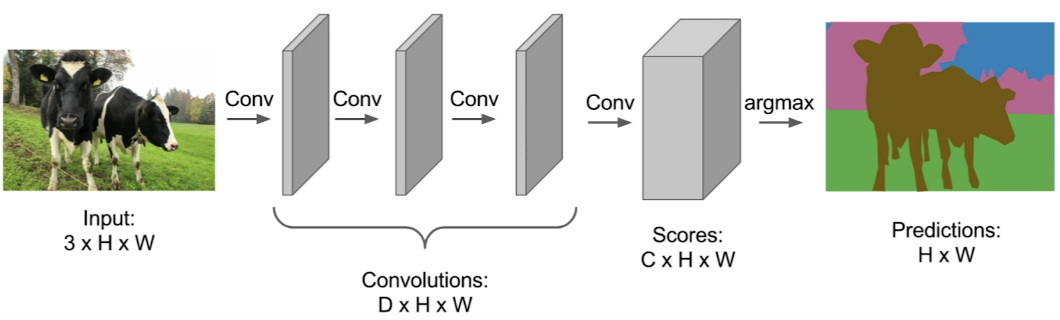
FCN architecture.
Predictions
This output Tensor of predictions contains values that classify every pixel in the image, so if we look at a single pixel in this output, we would see a vector that looks like a classification vector -- with values in it that show the probability of this single pixel being a cat or grass or sky, and so on. We could do this pixel level classification all at once, and then train this network by assigning a loss function to each pixel in the image and doing backpropagation as usual. So, if the network makes an error and classifies a single pixel incorrectly, it will go back and adjust the weights in the convolutional layers until that error is reduced.
Limitations of This Approach
- It's very expensive to label this data (you have to label every pixel), and
- It's computationally expensive to maintain spatial information in each convolutional layer
So…
Downsampling/Upsampling
Instead, what you usually see is an architecture that uses downsampling of a feature map and an upsampling layer to reduce the dimensionality and, therefore, the computational cost, of moving forward through these layers in the middle of the network.
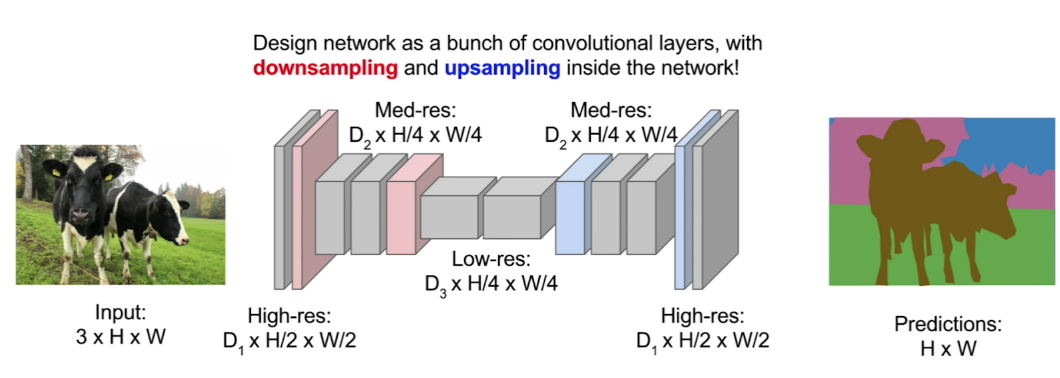
Downsampling/upsampling an an FCN.
So, what you’ll see in these networks is a couple of convolutional layers followed by downsampling done by something like maxpooling, very similar to a simple image classification network. Only, this time, in the second half of the network, we want to increase the spatial resolution, so that our output is the same size as the input image, with a label for every pixel in the original image.